Software-Umsetzung
Instanziierung
Der Generator wird in der Datei simLib_01.py bereitgestellt.
simLib_01.py
1 2 3 4 5 6 7 | |
Die class BatchProz() erwartet die Parameter:
T: Abtastzeit in Sekundencfg: Dict
Interpolation der Zeitreihen
Der Aufruf von genTS() berechnet einen Zeitschritt. Beim nächsten Aufruf wird automatisch der Zeitschritt weitergetaktet, was die Verwendung stark vereinfacht, aber eben auch beachtet werden muss.
Rückgabewerte
t0Zeitwert im Batch [s]tGZeitwert seit Simulationsstart [s]cntGBatch-Zyklen-Zähler seit SimulationsstartyListe der Simulationswerte
Test-Umgebung PLOT
Für die Entwicklung eines Simulationsmodells ist es hilfreich, für eine vorgegebene Anzahl von Zeitschritten eine grafische Ausgabe zu erzeugen. Mit dem Skript przSIM_plt_0x.py steht eine sehr einfache Anwendung von
Im wesentlichen werden die N=... Werte in einer Schleife mit genTS() berechnet und in ein numpy-Array abgelegt.
Ausschnitt: przSIM_plt_.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
Der Zugriff auf die Klassenvariable xLst ermöglicht den Zugriff auf Eigenschaften der einzelnen Prozesszustandsgrößen, wie sie in der toml-Datei vorgegeben wurden:
- name: Name der Größe (Bezeichner im Sinne der Eindeutigung einer Variablen)
- meta.unit: Einheit
- meta.min: Minimum
- meta.max: Maximum
Realtime-Umsetzung
Die Simulation soll als "Pseudo"-Prozess bei der Software-Entwicklung kontinuierlich Daten liefern. Diese Daten werden entweder in Datenbanken gespeichert oder Dashboard-Apps zur Verfügung gestellt. Daher ist ein Zeitstempel eine wichtige Information. In Python gibt es verschiedene Möglichkeiten, einen zeitzyklischen Rechenprozess zu realisieren. Der einfachste Weg mit Boardmitteln nutzt die Funktion time.sleep():
time.sleep()
1 2 3 4 5 6 | |
Allerdings hat diese Lösung den Nachteil, dass die Abtastzeit rechenzeitabhängig schwankt. Daher empfiehlt sich eine spezielle thread-orientierte Lösung einzusetzen: APscheduler siehe pypi
Die nachfolgendne Lösungen basieren auf dem Release 3.10. Eine minimale Anwendung zeigt das nachfolgende Listing:
apscheduler
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
Info
In der Version 4 wird es eine Reihe von Veränderungen und Erweiterungen geben, die in das Projekt eingearbeitet werden.
Kommunikationsschnittstellen
Hier sollen die für die IoT-Anwendungen im industriellen Umfeld relevanten Kommunikationsschnittstellen realisiert werden. Auf eine ausführliche Einführung in die Kommunikationskonzepte wird hier nicht eingegangen.
MQTT
MQTT setzt einen Broker voraus. Dieser wickelt den gesamten Datenverkehr ab. MQTT basiert auf dem Publish-Subscriber-Konzept. Diese Realisierung basiert auf dem paho-mqtt Paket für Python, das eine sehr einfache und effiziente Implementierung ermöglicht. Als Broker hat sich der Mosquito Broker bewert. Als Tool Zur Beobachtung des MQTT-Datenverkehrs auf dem Broker setzen wir den MQTT-Explorer ein.
Das Beispielskript published das gesamte json-Objekt. Das hat den Vorteil, dass dieses json-Objekt mit einem Timestamp versehen als Paket bzw. Message über den Broker von einem Client subscribt werden kann. So kann das json-Objekt direkt mit seiner Struktur in einer dokumentenorientierte Datenbank abgelegt werden kann.
Simulationsfunktion und Publisher
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
Mit dem MQTT-Explorer läßt sich der Datenverkehr im Broker gut beobachten:
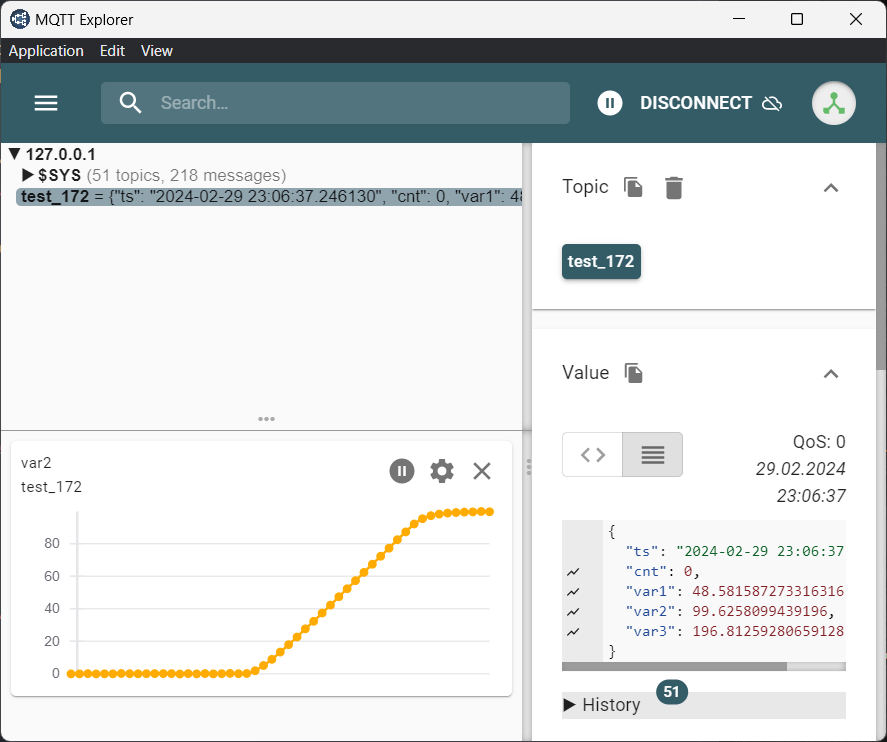
OPC-UA
Mit der industriellen Kommunikation OPC-UA steht eine leistungsfähige Kommunikationsmechanismus zur Verfügung. Als Demo wird hier ein sehr einfacher OPC-UA Server realisiert (Ohne method, events, ...), der auf dem FreeOpcUa basiert. Die Bibliothek asyncua stellt sowohl asynchrone als auch synchrone Kommunikationsmechanismen zur Verfügung. Die Implementierung lässt sich genau wie die MQTT-Variante umsetzen. Der Echtzeit-Job übergibt die Simulationsdaten an den OpcUa-Server mv.write_value(y0[i]). Die Anfragen der externen Clients bearbeitet der OpcUa-Server dann vollständig selbständig.
| Initialisierung der OpcUa-Kommunikation | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
Simulationsdaten an den OpcUa-Server:
| Daten an OpcUa-Server | |
|---|---|
1 2 3 4 5 6 7 | |
Die Funktion des OpcUa-Servers lässt sich mit dem Tool UA Expert interaktiv visualisieren, wie der Screenshot zeigt:
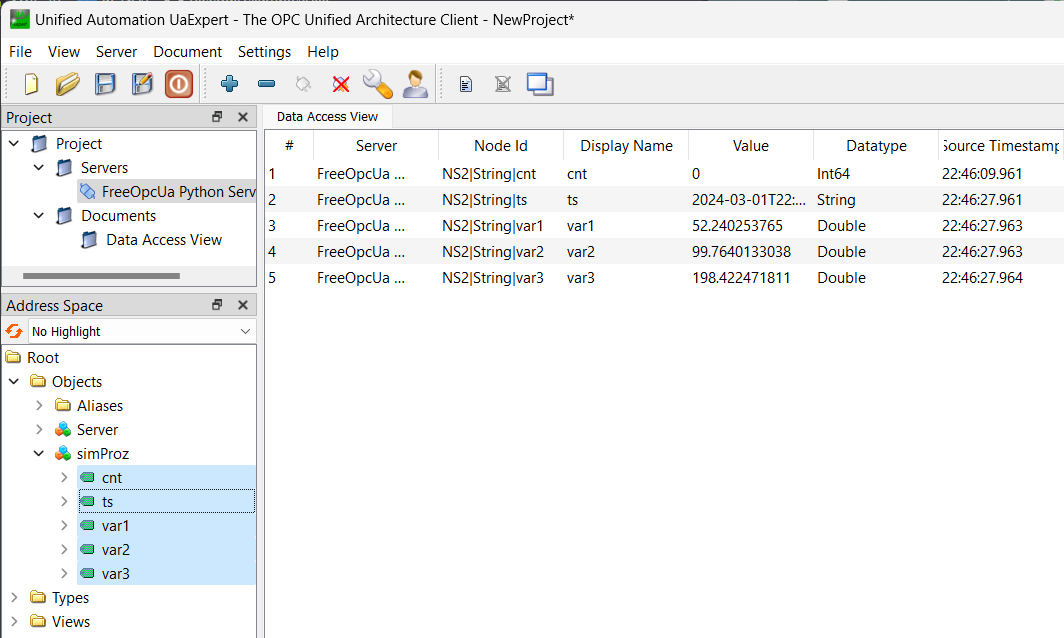
RESTapi
Die RESTapi oder RESTful API (Application Programming Interface) oder Web-API, unterliegt den Beschränkungen der REST-Architektur und ermöglicht Interaktionen mit RESTful Webservices. In diesem Beispiel werden 2 Endpoints realisiert. Der erste Endpoint meta wird die Metadaten der Simulationsstruktur an den Client ausliefern. Der Endpoint data wird die Value's zu den einzelnen Signalen mit den Timestamp zusammen ausliefern. Die Realisierung hier wird mit dem Framework Fast API umgesetzt. Als Serverdienst wird uvicorn eingesetzt.
Sim-Server
Die Simulation wird wie bisher auch als Echtzeitprozess gestartet und hält die Simulationsergebnisse als Properties.
| SimProz | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
Die beiden Endpoints werden mit den Decorators wie folgt definiert:
| Endpoints | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Die Serverdienste:
| Server | |
|---|---|
1 2 3 4 5 6 | |
Client-Beispiel: Swagger-UI
Fast API bringt einen interaktiven Browser-Client Swagger-UI zum Erkunden und Testen der RestAPI-Schnittstelle mit. Diese Anwendung kann mit {IP-Adresse}:{Port}/docs (Endpoint docs) im Browser aufgerufen werden:
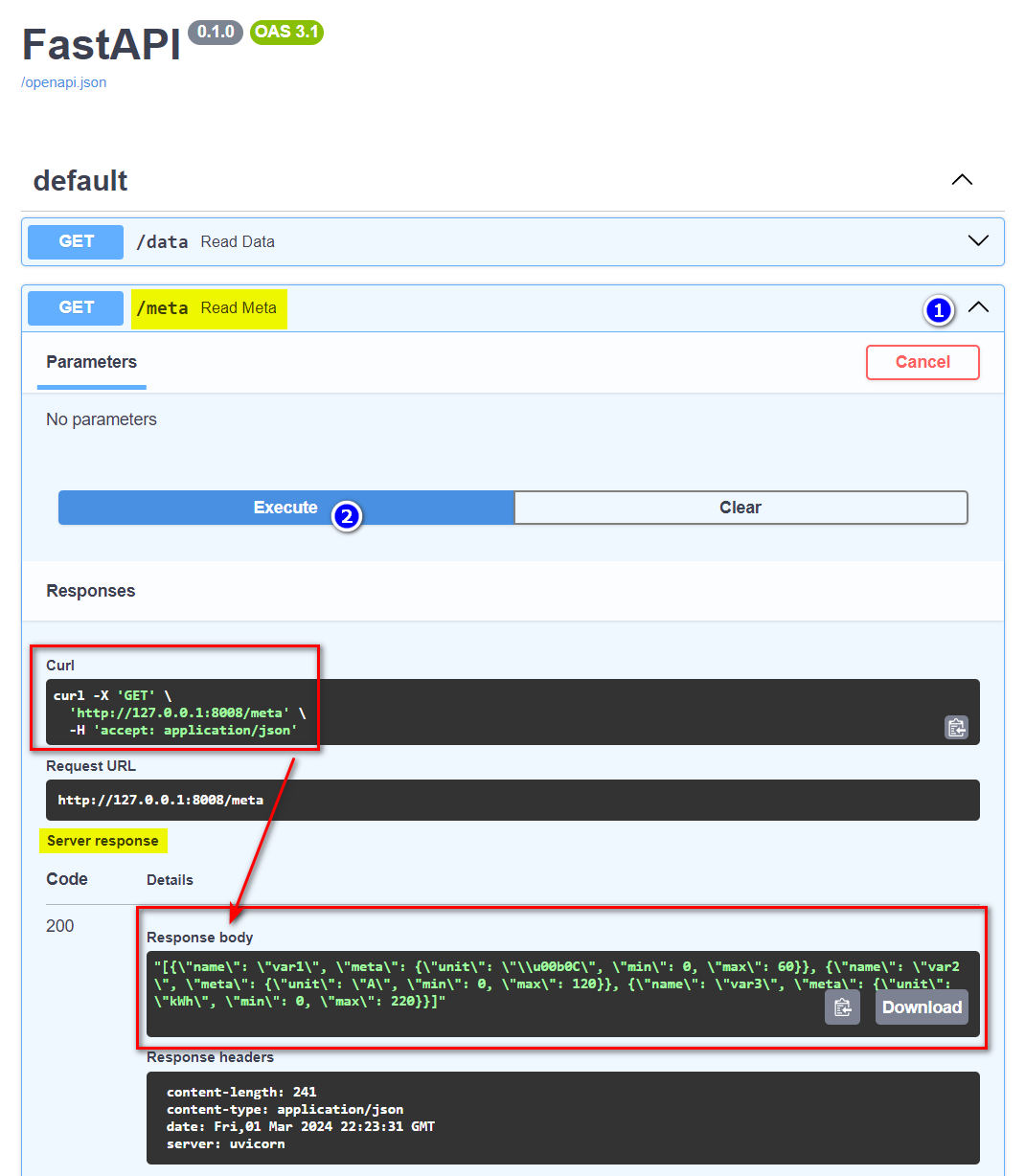
Client-Beispiel:
Ein GET-Request lässt sich in einem Python-Skript sehr einfache umsetzen. Dazu steht die Bibliothek requests zur Verfügung. Und es braucht lediglich die vollständige URL mit Endpoint angegeben werden und.
| GET-Requests | |
|---|---|
1 2 3 4 5 6 7 8 9 10 | |
Die Antworten:
[
{
"name": "var1",
"meta": {
"unit": "\u00b0C",
"min": 0,
"max": 60
}
},
{
"name": "var2",
"meta": {
"unit": "A",
"min": 0,
"max": 120
}
}
]
{
"ts": "2024-03-01 23:47:08.308112",
"cnt": 8,
"var1": 46.46386301671156,
"var2": 92.5501867734563
}
ZMQ
Ein schlichtes und leistungsfähiges Kommunikationsmechanismus, der Websockets aufsetzt, ist ZeroMQ. 0MQ kann sowohl Client-Server- als auch Publish-Subscribe-Mechanismen anbieten. Hier wird um den
| SimPro + 0MQ-Server | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | |
Datenbanken
Für das Loggen von Zeitreihen werden hier die zwei gängigsten NoSQL-Datenbanken genutzt.
MongoDB
Die MongoDB ist eine dokumentenorientierte Datenbank, die frei verfügbar für Windows und Linux ist. Für Python wird das Paket mongodb genutzt.
Für die datenbankgestützte Entwicklung kann es sehr hilfreich sein, dass die Zeitreihe der Simulationsdaten nicht nur in einem festen Zeitraster (Abtastzeit T ).
MongoDB - Code-Sequenz
| SimPro + MongoDB-Client | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 | |
Bei der Definition des Collection als werden wesentliche Eigenschaften festgelegt.
timeseries={
"timeField": "ts",
"metaField": "loc",
"granularity": "seconds"
},
expireAfterSeconds = cfg.expire # Ablauf der Gültigkeit von Datensätzen
InfluxDB
Die InfluxDB ist eine reine Zeitreihen-Datenbank und läuft auf allen System - auch auf einen RaspberryPi!
Für Python wird das Paket influx-client genutzt. Es kann mit der InfluxDB >= Version 2 arbeiten ( Tutorial )
InfluxDB - Code-Sequenz
| SimPro + InfluxDB-Client | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 | |
Requirements
Für die Nutzung der zahlreichen Beispiele müssen eine Reihe von Bibliotheken installiert werden. Am einfachsten gelingt dies mit dem pip-Befehl:
Cmd
py -m pip install -r req.txt
pip install -r req.txt
Requirements req.txt
numpy
APScheduler
pandas
influx-client
pymongo
paho-mqtt
asyncua
asyncio
fastapi
uvicorn
requests
Installation als Linux-Dienst
Für automatische Ausführung eines Python-Skripts muss ein Dienst == serice eomngerichtet werden Link.
| sim.service | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
Wird das py-Skript mit einer virtuellen Python-Umgebung gestartet, dann ist z.B. zu ändern:
| .venv | |
|---|---|
6 | |
Wenn z.B. der Port eines Webservers auf Port 80 laufen soll, dann muss das Python-Skript mit root-Rechten ausgeführt werden:
| root | |
|---|---|
12 | |
Folgende Arbeitsschritte sind für die Installation und der Steuerung des Dienstes erforderlich:
Service an den richtigen Ort kopieren (/etc/systemd/systemm )
sudo cp /home/pi/py/sim/sim.service /etc/systemd/system/sim.service
sudo systemctl start sim.service
sudo systemctl stop sim.service
sudo systemctl enable sim.service
sudo systemctl restart sim.service
Status abfragen
sudo systemctl status sim.service
man systemctl